Highly structured semantics
IE covers entity extraction, relation extraction, and event extraction, all requiring explicit semantic structures instead of shallow recognition.
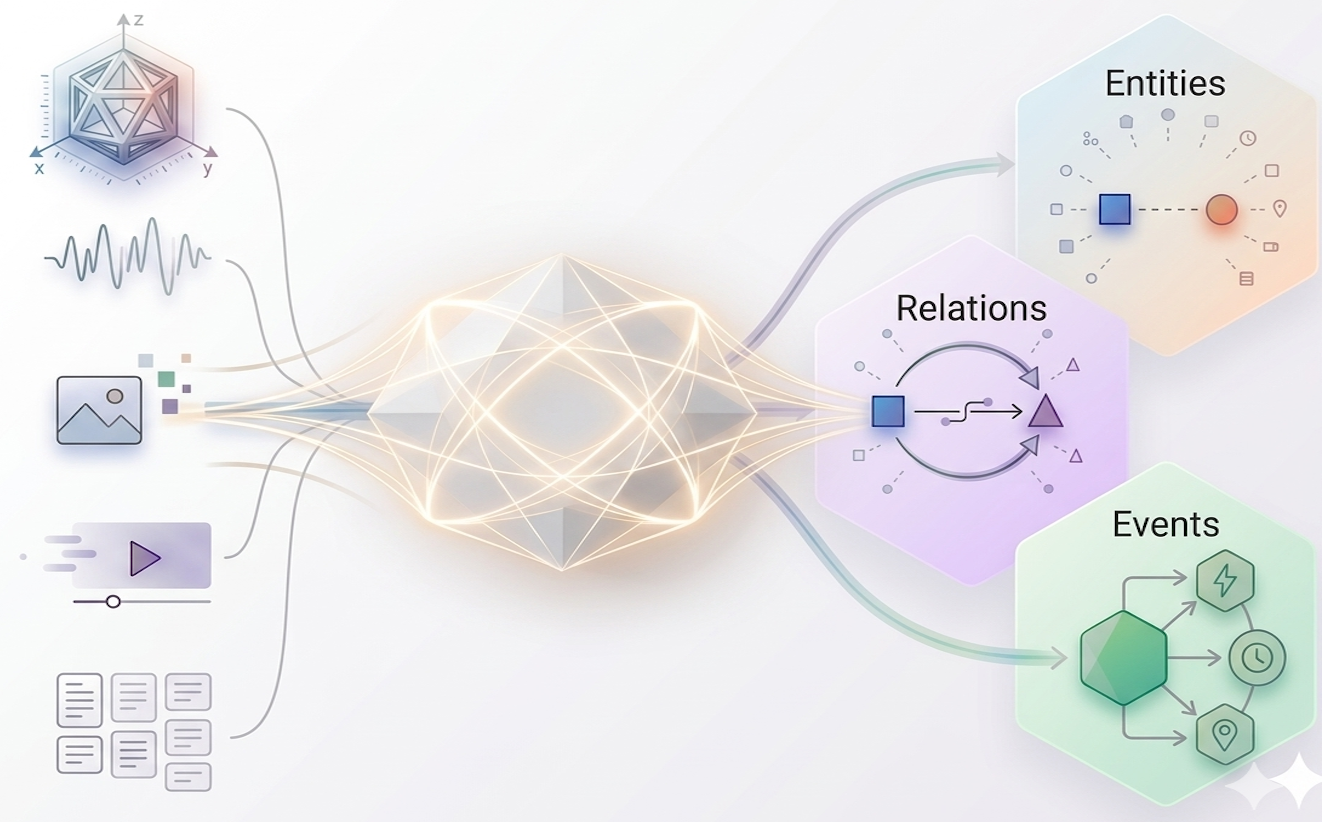
Unified Multimodal Information Extraction (Uni-IE) studies information extraction as a unified structured semantic parsing problem across entities, relations, and events, while extending the input space from text to images, video, speech, and broader multimodal compositions. Rather than treating each extraction task and each modality in isolation, this thread asks how one coherent modeling view can connect them. This unified approach significantly enhances the model's ability to generalize across new domains, providing a robust framework for real-world intelligence that demands high-precision knowledge synthesis.
IE covers entity extraction, relation extraction, and event extraction, all requiring explicit semantic structures instead of shallow recognition.
Real-world IE evidence may come from language, images, video, speech, documents, or their combinations, with fine-grained grounding demands.
A unified formulation can align tasks, modalities, and decoding paradigms, making IE systems more reusable, scalable, and structurally consistent.
Research Papers
Workshop
Survey Papers